

Alpha Go Zero vs Agentic RAG
Comparative Analysis of Autonomous Task Execution

The evolution of artificial intelligence has given rise to diverse approaches to autonomous task execution, each tailored to different domains and challenges. Among these, AlphaGo Zero and Agentic RAG stand out as notable examples of sophisticated AI systems. While AlphaGo Zero represents a pinnacle of AI achievement in game-playing, Agentic RAG showcases a leap towards more flexible, knowledge-driven systems capable of tackling complex, real-world tasks. This article delves into a comparative analysis of these two approaches, exploring their strategies, adaptations, and potential synergies. This article is intended to provide a high-level overview of the key distinctions between AlphaGo Zero and Agentic RAG in response to a query raised on a LinkedIn forum. While this exposition does not aim to be exhaustive or deeply technical, it serves to collate and summarize the primary contrasts between these two AI approaches.
Hierarchical Reinforcement Learning in AlphaGo Zero
AlphaGo Zero, developed by DeepMind, employs a hierarchical reinforcement learning approach to master the game of Go—a complex, rule-based environment demanding strategic depth and foresight. The system learns from scratch through a self-play mechanism, allowing it to explore and develop strategies beyond human expertise. Key components of AlphaGo Zero include:
Self-Play Mechanism: AlphaGo Zero starts with no human input, learning entirely through self-play. This autonomous learning approach enables the system to generate novel strategies that exceed existing human knowledge.
Monte Carlo Tree Search (MCTS): The system uses MCTS to navigate the vast game tree, balancing the exploration of new moves with the exploitation of known successful strategies. This probabilistic decision-making process is crucial for managing the immense search space in Go.
Neural Network Integration: A single neural network performs dual roles—evaluating positions and guiding the search—streamlining the decision-making process compared to earlier versions that utilized separate policy and value networks.
Agentic RAG’s Approach
Agentic RAG represents a paradigm shift from specialized, game-focused AI to systems designed for open-ended, real-world tasks. Leveraging Llama 3.1 models and NVIDIA NeMo Retriever, Agentic RAG employs a retrieval-augmented generation (RAG) approach that integrates large language models with external knowledge retrieval to enhance response accuracy and mitigate hallucinations. Its key features include:
Retrieval-Augmented Generation: This approach combines the generative capacity of language models with retrieval mechanisms, enhancing the system’s accuracy and grounding responses in external, domain-specific knowledge.
Tool Integration: Agentic RAG extends beyond simple query-answer tasks by incorporating tool use and multi-step reasoning, allowing it to access external data sources and perform complex problem-solving.
Dynamic Adaptation: Unlike static systems, Agentic RAG dynamically adjusts its approach based on context and feedback, making it well-suited for ambiguous and evolving tasks.
Comparative Analysis: AlphaGo Zero vs. Agentic RAG
The following table provides a detailed comparison of AlphaGo Zero and Agentic RAG across various dimensions:
Key Similarities
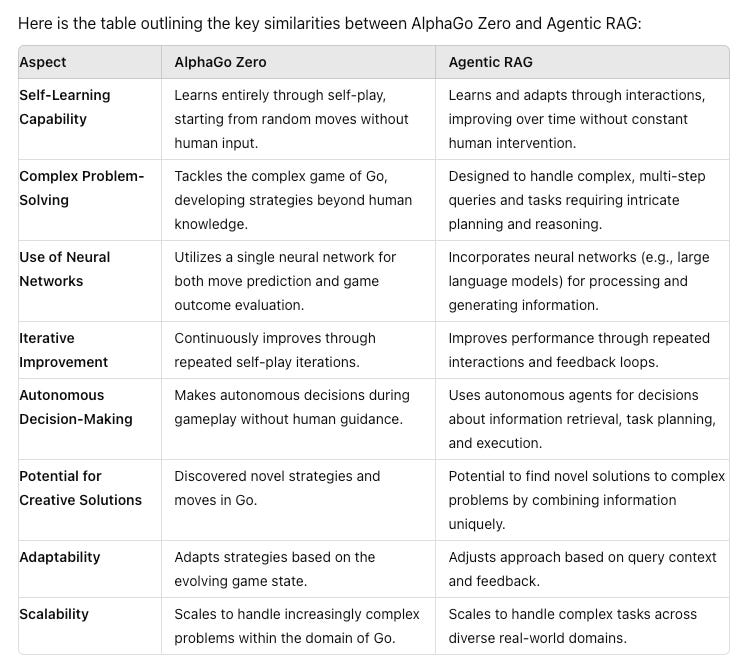
Key Differences
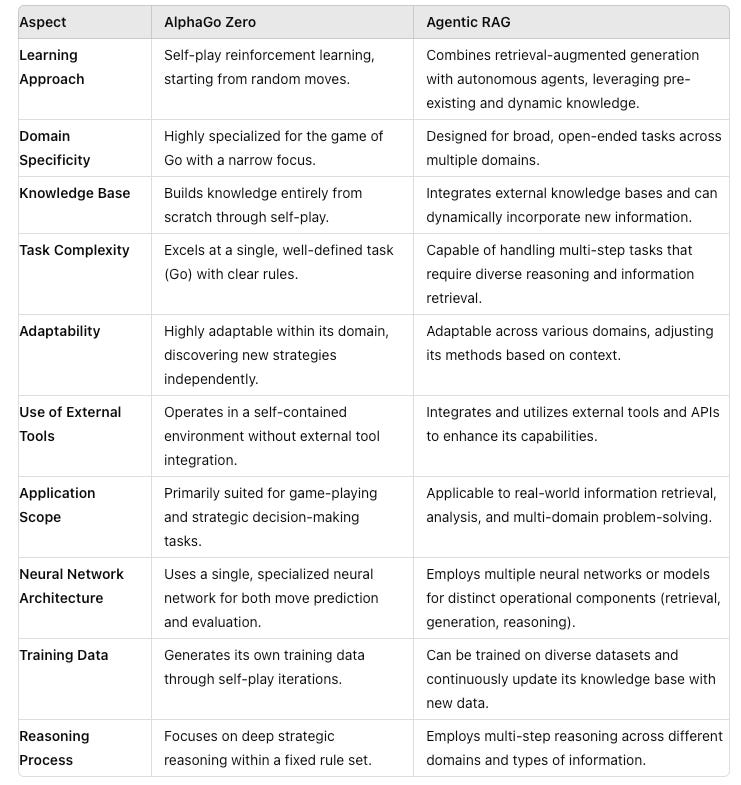
Adaptations for Real-World Tasks
Agentic RAG incorporates several critical adaptations to bridge the gap between structured, rule-based AI and the demands of real-world environments:
Ambiguity Handling: Utilizing probabilistic reasoning and large-scale language models, Agentic RAG can interpret and respond to ambiguous inputs, unlike AlphaGo Zero, which is limited to deterministic gameplay.
Domain-Specific Knowledge Integration: Through retrieval mechanisms, Agentic RAG dynamically incorporates external knowledge, enhancing its ability to provide contextually relevant responses tailored to specific user queries.
Task Decomposition and Tool Use: By decomposing tasks into subcomponents and using integrated tools, Agentic RAG can address complex, multi-step problems that are characteristic of real-world scenarios, expanding its operational scope far beyond the fixed strategies of game AI.
Feedback-Driven Adaptation: Agentic RAG’s architecture allows for continuous refinement through user feedback and environmental interaction, employing algorithms like PPO to dynamically adjust strategies, unlike the fixed policy updates in AlphaGo Zero.
Synergies and Future Directions
Despite their divergent architectures, the potential synergies between AlphaGo Zero and Agentic RAG are substantial. Integrating the hierarchical planning and reinforcement learning strengths of AlphaGo Zero with the retrieval and adaptability of Agentic RAG could yield a hybrid model capable of handling both deterministic and ambiguous environments.
Hierarchical Planning for Task Decomposition: Agentic RAG could leverage hierarchical reinforcement learning to better manage task decomposition, applying AlphaGo Zero’s approach to break down complex, multi-step tasks into manageable actions.
Self-Improvement Mechanisms: By incorporating AlphaGo Zero’s self-play and continuous learning mechanisms, Agentic RAG could enhance its ability to autonomously refine its performance over time, learning from interactions and feedback.
Hybrid Architectures: Future AI systems might integrate the strengths of both approaches, employing reinforcement learning for strategic sub-tasks within a broader, retrieval-augmented framework. This hybrid model could exploit the strategic foresight of reinforcement learning while maintaining the flexibility and knowledge integration of RAG systems.
Conclusion
The comparative analysis of AlphaGo Zero and Agentic RAG underscores the breadth of AI’s evolution, from specialized game-playing algorithms to versatile, knowledge-driven systems capable of addressing complex, real-world challenges. AlphaGo Zero exemplifies the depth of strategic planning and mastery within a deterministic framework, whereas Agentic RAG embodies the adaptability and broad applicability necessary for dynamic task execution across diverse domains.
The future of autonomous task execution likely lies in bridging these methodologies, combining the hierarchical depth of reinforcement learning with the expansive knowledge and adaptability of retrieval-augmented language models. Such hybrid systems would not only execute tasks but also learn and optimize autonomously, embodying a more holistic approach to AI-driven problem solving in both structured and unstructured environments.