

Training a Large Language Model Across 1,000 GPUs
Engineering the Illusion of a Single Brain

There is a persistent myth in large-scale AI training: that scaling to 1,000 GPUs is a compute problem.
It is not.
It is a consistency problem.
When you train a large language model across ~1,000 GPUs, the true engineering objective is not parallelization. It is this invariant:
There must exist exactly one logical model state being optimized, even though computation is distributed.
If that invariant fractures, you are no longer training a single model. You are running 1,000 loosely coordinated experiments.
Everything else, data sharding, tensor parallelism, networking, checkpointing, orchestration, is engineering in service of that invariant.
Let’s unpack the system the right way: as an owner, not as someone reacting to symptoms.
The System Boundary
We define the system as the distributed training runtime that:
Consumes curated, tokenized dataset shards
Executes forward/backward passes across ~1,000 GPUs
Synchronizes gradients
Applies optimizer updates
Produces consistent checkpoints
Recovers deterministically from failure
Out of scope: upstream raw data pipelines and inference serving.
This boundary discipline matters. Ambiguous systems collapse under scale.
The Core Invariant: One Logical Model State
At scale, parameters may be:
Replicated
Sharded
Materialized temporarily
Partitioned across tensor-parallel groups
But logically, there is one evolving parameter vector.
This is enforced at a specific architectural boundary:
The Optimizer Step Barrier
The system implements Bulk Synchronous Parallel (BSP) semantics at optimizer step boundaries.
At that barrier:
Gradients across each Data Parallel (DP) group are aggregated.
Optimizer state is updated atomically.
All ranks advance to the next global step together.
No partial commits.
No asynchronous weight drift.
This barrier is the heartbeat of correctness.
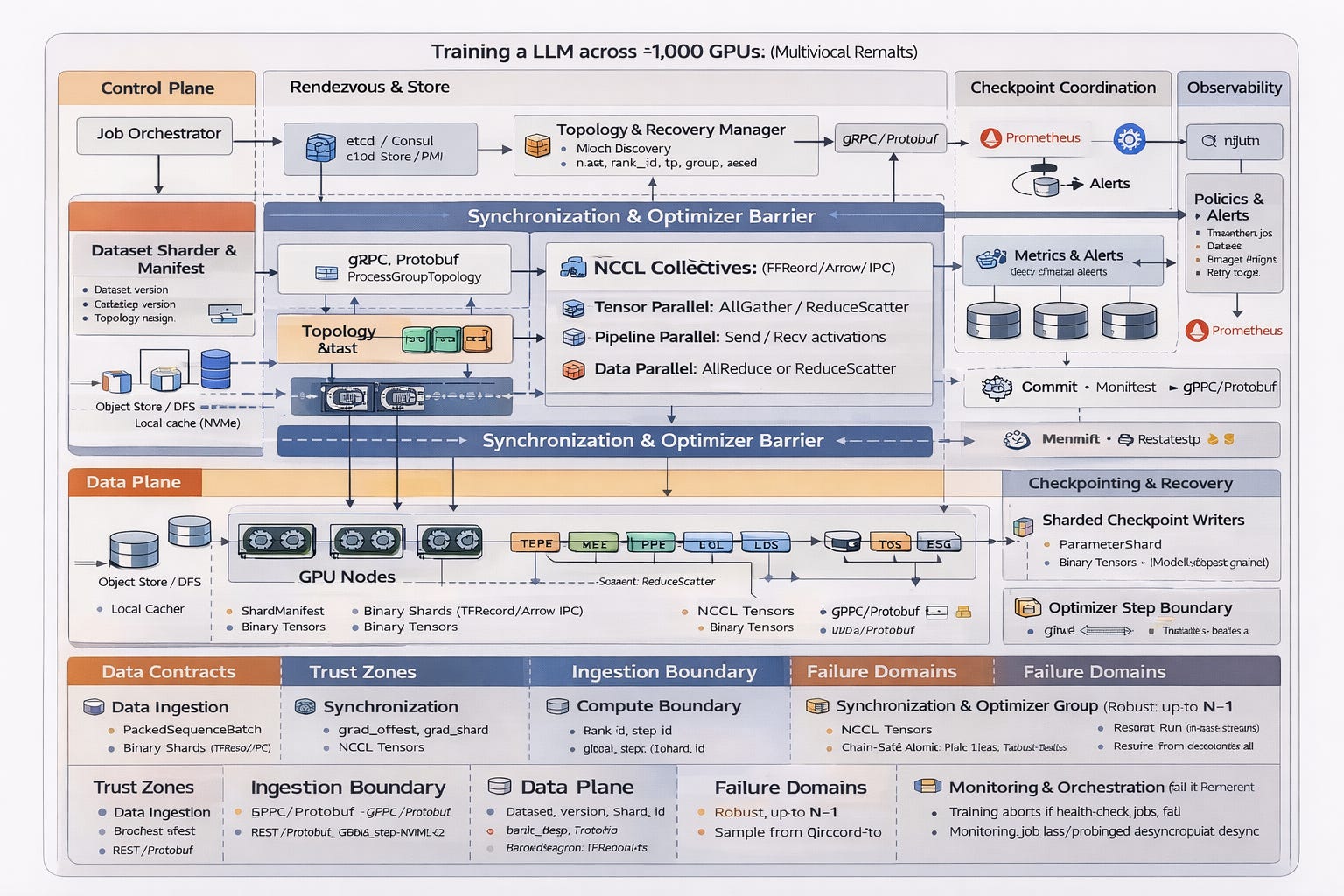
The Architecture Planes
The system decomposes cleanly into five planes.
1. Control Plane
The control plane schedules and supervises the training job.
Components:
Job Orchestrator
Rendezvous / Process Group Store
Topology Manager
Responsibilities:
Allocate GPU nodes
Assign ranks
Define TP/PP/DP topology
Inject runtime configuration
Important detail:
The control plane is not in the training hot path.
Gradient synchronization never uses RPC. It uses GPU collectives.
Separation of concerns is non-negotiable.
2. Rendezvous & Topology
Before training begins, ranks must discover each other and form communicators.
Using a distributed store (e.g., etcd or c10d):
Ranks join
Communicator IDs are exchanged
TP, PP, and DP groups are constructed
This mapping is versioned and embedded into checkpoints.
If topology at restore does not match topology at save, the job aborts.
Topology drift is silent corruption.
3. Data Plane
The data plane feeds the GPUs.
Dataset Sharder
Produces deterministic shard manifests:
dataset_version
tokenizer_version
shard_id
sample_ids
The manifest is JSON.
The shard payload is binary (WebDataset / TFRecord / Arrow IPC).
JSON is never used on the hot path.
Data Loader
Each rank:
Reads its shard
Produces PackedSequenceBatch tensors
Maintains deterministic replay state
Restart semantics require restoring:
RNG state
Dataloader cursor
Shard offsets
If you cannot resume deterministically, you cannot debug convergence.
4. GPU Compute Layer
Each GPU rank performs:
Forward pass
Backward pass
Local gradient accumulation
Precision:
BF16 preferred
Loss scaling if FP16
Metrics emitted:
Step time
Gradient norm
Loss
Overflow counts
This layer is compute-bound.
The next layer is coordination-bound.
5. Synchronization & Optimizer Barrier
This is the core of the distributed system.
NCCL Collectives
All synchronization uses GPU collectives:
NVLink intra-node
InfiniBand/RDMA inter-node
Operations:
Tensor Parallel → AllGather / ReduceScatter
Pipeline Parallel → Send/Recv activations
Data Parallel → AllReduce or ReduceScatter
These are synchronous collectives.
No gRPC. No REST. No request/response.
When communication dominates more than ~30% of step time, scaling efficiency collapses.
Optimizer Step Barrier
The optimizer update is the global consistency boundary.
Inputs:
Aggregated gradients
Optimizer state shards
Learning rate scheduler state
Outputs:
Updated parameter shards
Incremented global step
Guarantee:
Every DP rank transitions to the same logical model state.
If any rank fails before the barrier completes, the step is invalidated.
This is the “single brain” illusion made real.
Checkpointing: Atomic or It Didn’t Happen
Checkpointing at 1,000 GPUs is not a file save.
It is a distributed commit protocol.
Each rank writes:
Parameter shard
Optimizer shard
RNG state
Then the coordinator:
Validates all shards exist
Computes checksums
Writes a manifest
Promotes manifest as the atomic commit marker
Only the manifest defines “latest checkpoint.”
Partial shards are never visible as complete state.
Deterministic Restart
A correct restart restores:
Parameters
Optimizer state
Scheduler state
RNG state
Data cursor
The test:
Run N steps.
Checkpoint.
Resume.
Run M more steps.
The result at N+M must match an uninterrupted run (within floating-point tolerance).
If it does not, you do not have reproducibility.
If you do not have reproducibility, you do not have debuggability.
Observability: The Hidden Architecture
You cannot operate 1,000 GPUs without telemetry discipline.
Metrics include:
Compute:
step_time_seconds
tokens_per_second
gpu_utilization
Communication:
collective_latency
retry_count
communication_time_ratio
Data:
dataloader_wait_time
cache_hit_ratio
Checkpoint:
checkpoint_duration
restore_time
Prometheus scraping is pull-based. Alerts are derived from SLO violations.
Silent failure modes are unacceptable.
Failure Domains
Failure is normal at this scale.
Single GPU failure:
Abort DP group
Restart from checkpoint
Node failure:
Restart
Checkpoint write failure:
Retry
Never commit partial state
Network degradation:
Alert
Abort if collective unstable
Graceful degradation is limited.
Consistency violations are never tolerated.
Performance Envelopes
A system without explicit targets is not engineered.
Typical envelopes:
Communication ≤ 30% of step time
GPU utilization ≥ 85%
Checkpoint commit ≤ T minutes
Restore ≤ R minutes
Deterministic restart verified in CI
Cost per billion tokens is tracked explicitly.
Scale without cost discipline is entropy.
What This System Actually Is
Distributed LLM training is not:
A collection of GPUs
A Kubernetes job
A checkpointing script
It is a distributed consensus system that happens to execute matrix multiplication.
The optimizer step barrier is the consensus boundary.
The manifest commit is the storage boundary.
The topology manager is the membership authority.
Everything else is plumbing.
The Real Discipline
Engineering maturity here is not about cleverness.
It is about:
Specifying invariants before scaling
Making contracts explicit
Separating planes cleanly
Designing for restart before failure
Observing before optimizing
Think twice. Code once.
At 1,000 GPUs, there is no margin for accidental architecture.
Scale amplifies design quality.
It also amplifies design debt.
The illusion of a single brain is fragile.
The system must protect it relentlessly.
Excellent piece on the engineering challenges of distributed training! The hardware coordination you describe is impressive.
There's also an interesting theoretical question regarding scaling: "Beyond Scaling Laws: Understanding Transformer Performance with Associative Memory," offering a different theoretical lens that complements the engineering perspective here.
Link: https://arxiv.org/abs/2405.08707